
Why Every PM Needs to Master AI Evals


📋 Your Complete AI Evaluation Roadmap
The Truth About AI Evaluation
The Driving Test Analogy
Three Types of AI Evaluation Every PM Needs
Real Companies, Real Results, Real Numbers
🔒 The Evaluation Framework I Use for Every AI Feature
🔒 Step-by-Step Workflow: How to Build Your First Eval
🔒 The Types of Evaluation That Will Save Your Product
Fairness and bias audits
Red teaming and adversarial testing
User studies and human feedback
🔒 The Three Biggest Mistakes I See PMs Make
🔒 How to Practice Without Waiting for Engineering
🔒 The Mindset Shift That Changes Everything
🔒 Your 30-Day AI Evaluation Challenge
🔒 Complete Resource Guide: Tools & References
The skill that separates AI products that thrive from those that die
BM invested heavily in Watson for Oncology. The AI was supposed to revolutionize cancer treatment by helping doctors make better decisions.
It failed spectacularly.
Not because the technology was bad. Not because the team wasn't smart. But because they fundamentally misunderstood how to evaluate their AI.
Watson looked great in controlled tests. The business case was solid. The technology seemed revolutionary. But when it reached real hospitals, doctors discovered the AI's recommendations often didn’t match local medical practices or align with clinical realities.
The program was ultimately discontinued, and IBM sold off most of its Watson Health assets in 2022.
Here's what hit me about that story: IBM had some of the smartest engineers and PMs in the world. Yet they missed something critical that cost them years of work and enormous investment.
They didn’t know how to properly evaluate their AI.
Let me tell you a truth about AI product management
Most product managers think AI evaluation is an engineering problem.
They're dead wrong.
AI evaluations (or "evals" as we call them) are actually the most important product skill you can develop right now. Here's why: writing good AI evals forces you to translate fuzzy human preferences into precise, measurable criteria.
That's literally the core of great product management.
Think about it this way. When you launch a traditional feature, you know pretty quickly if it works. The button either works or it doesn't. Users either convert or they don't.
But AI? An AI can give you a response that sounds perfectly reasonable but is completely wrong. It can work great for 95% of users and catastrophically fail for the other 5%. It can perform beautifully in testing and then drift over time in production.
Without proper evaluation, you're flying blind.
And here's the kicker: As Kevin Weil, CPO at OpenAI, recently said: "Writing evals is going to become a core skill for product managers. It is such a critical part of making a good product with AI."
The driving test that changed how I think about AI
The best way I've found to explain AI evals to non-technical teammates is the driving test analogy.
You wouldn't let someone drive just because they can start a car, right? You test them on:
Awareness: Can they read road signs and react to changing conditions?
Decision-making: Do they make good choices when things get unpredictable?
Safety: Can they consistently follow rules and avoid harm?
AI evaluation works exactly the same way. You're not just checking if your AI works—you're checking if it works well, safely, and reliably across all the scenarios your users will throw at it.
But here's where it gets interesting: unlike a driving test, AI evaluation never ends. Your AI can pass all its tests today and start failing tomorrow as user behavior shifts or the model drifts.
This is why traditional software testing approaches fall short with AI. The fundamental difference comes down to one key concept: determinism.
Traditional software is deterministic—given the same input, it will always produce the same output. When you click "login" with the correct credentials, you'll always get logged in. When you run 2+2 in a calculator, you'll always get 4.
AI systems are non-deterministic—they use probability and randomness in their decision-making. Ask the same AI the same question five times, and you might get five slightly different answers. This isn't a bug; it's a feature that allows AI to be creative and handle ambiguous situations.
Traditional Software Testing vs. AI Evaluation
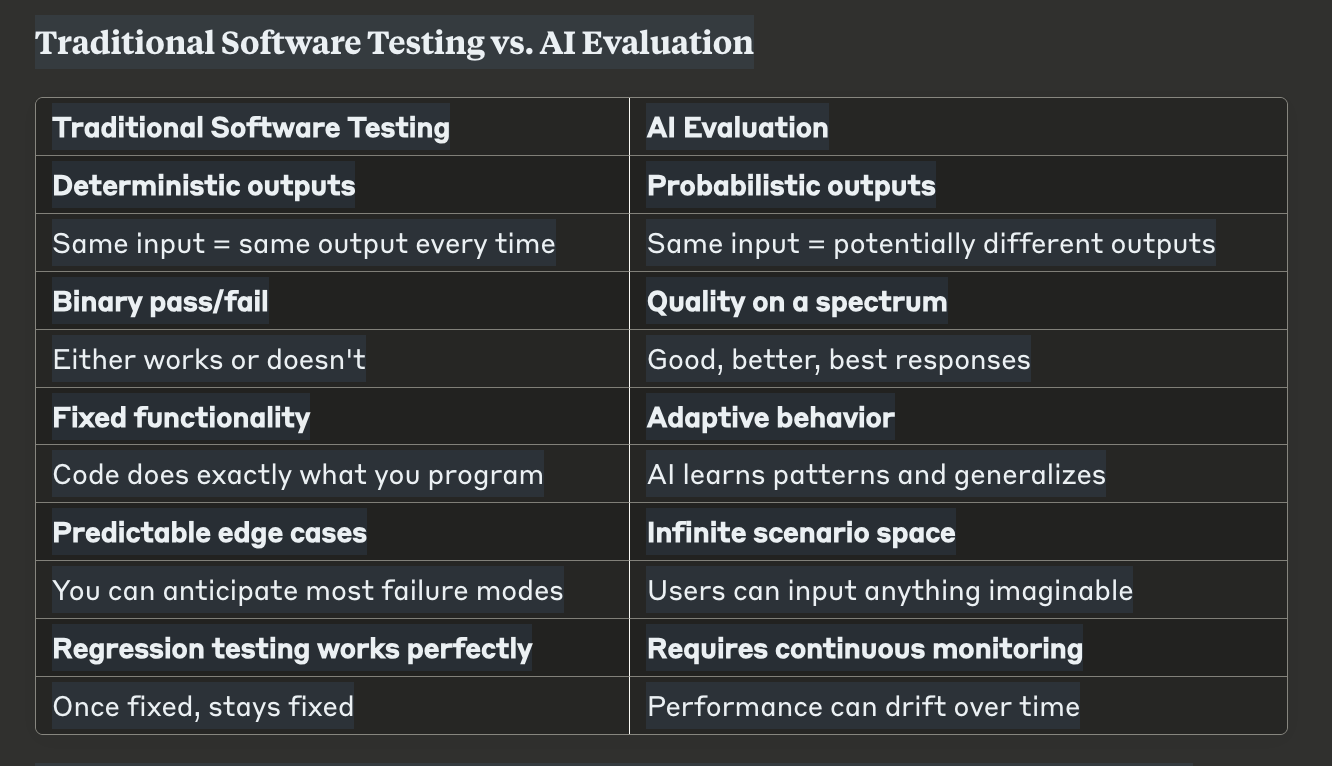
Traditional testing is like checking if a train stays on its tracks—straightforward, deterministic, clear pass/fail scenarios.
AI evaluation is more like giving someone a driving test in busy city traffic. The environment is variable, the system makes judgment calls, and you're evaluating how well they drive, not just whether they can drive.
The three types of AI evaluation every PM needs to know
After studying how companies like Microsoft, Google, and Anthropic approach this, I've found there are really three core evaluation approaches:
Human evaluations
Real people rate your AI's outputs. This is your gold standard for subjective stuff like "Does this email sound professional?" or "Is this response helpful?"
The upside? Nothing beats human judgment for nuanced quality assessment.
The downside? It's expensive and doesn't scale. But for high-stakes decisions or establishing your quality bar, human evaluation is essential.
Code-based evaluations
Automated checks that verify objective criteria. Think: "Does the AI return valid JSON?" or "Is the response under 500 characters?"
These are fast, cheap, and deterministic. Perfect for catching format errors or basic compliance issues.
But they can only check things you can measure with code. They miss the nuanced stuff that makes AI outputs truly valuable.
LLM-as-judge evaluations
Using another AI to evaluate your AI. This is the sweet spot most PMs should focus on—it scales better than humans but handles subjective criteria better than code.
You can prompt an AI evaluator to check for things like "Is this response relevant to the user's question?" or "Does this maintain a professional tone?"
Here’s the kind of prompt I use to direct an LLM to be an evaluation judge:
You are an expert product evaluator. Your job is to objectively assess the quality of AI-generated responses based on the following criteria:
Relevance: Does the response directly answer the user’s question or fulfill their intent?
Helpfulness: Is the information complete, actionable, and clear?
Tone: Is the response professional, polite, and aligned with brand guidelines?
Accuracy: Is all provided information factually correct and well-supported?
Score the response on a scale of 1 to 5, with 5 being excellent and 1 being poor. Provide a concise explanation for your score. If the response fails any critical criteria (e.g., gives harmful or unsafe advice), assign a 1 and clearly state the issue.
The winning combination? Start with LLM-as-judge for scale, then use human evaluation to validate your most important use cases.
Real companies, real results, real numbers 📊
Real companies, real results, real numbers 📊
Let’s talk about what happens when you actually implement this stuff properly.
Microsoft and other industry leaders have described how building comprehensive evaluation frameworks for their AI systems is critical for reliable deployments. These frameworks mix automated checks, human reviews, and continuous monitoring to support products worldwide. See Microsoft’s Responsible AI resources for examples.
Harvard Business School ran a large controlled study with over 750 consultants using GPT-4. The results? Consultants with AI completed 12.2% more tasks, worked 25.1% faster, and delivered work rated 40% higher quality—especially on less complex tasks. But here’s the kicker: performance dropped when the AI was pushed beyond its capabilities.
OpenAI, Google, and Anthropic have documented that robust evaluation pipelines—including automated and human checks, fairness audits, and red-teaming—are foundational for every major AI launch. For technical deep-dives, see:
OpenAI’s GPT-4 Technical Report
Google’s AI Principles
The pattern is clear: companies that invest in AI evaluation see faster product cycles, better model reliability, and higher-quality results at scale.
Keep reading with a 7-day free trial
Subscribe to The Product Channel By Sid Saladi to keep reading this post and get 7 days of free access to the full post archives.