


#110 Beyond Traditional RAG: Advanced Knowledge Retrieval Architectures

🚀 The RAG Revolution Is Evolving
Retrieval-Augmented Generation (RAG) has transformed AI applications by grounding responses in reliable information sources. As RAG architectures continue to advance, innovative approaches are addressing earlier limitations and expanding what's possible for AI-powered knowledge systems.
This week, we explore how next-generation RAG architectures are evolving to meet enterprise needs, and what this means for your product strategy.
The Evolution of RAG Architecture
Traditional RAG approaches have provided significant value by connecting LLMs to external knowledge sources. However, as implementations have matured, teams have identified opportunities for improvement in several key areas.
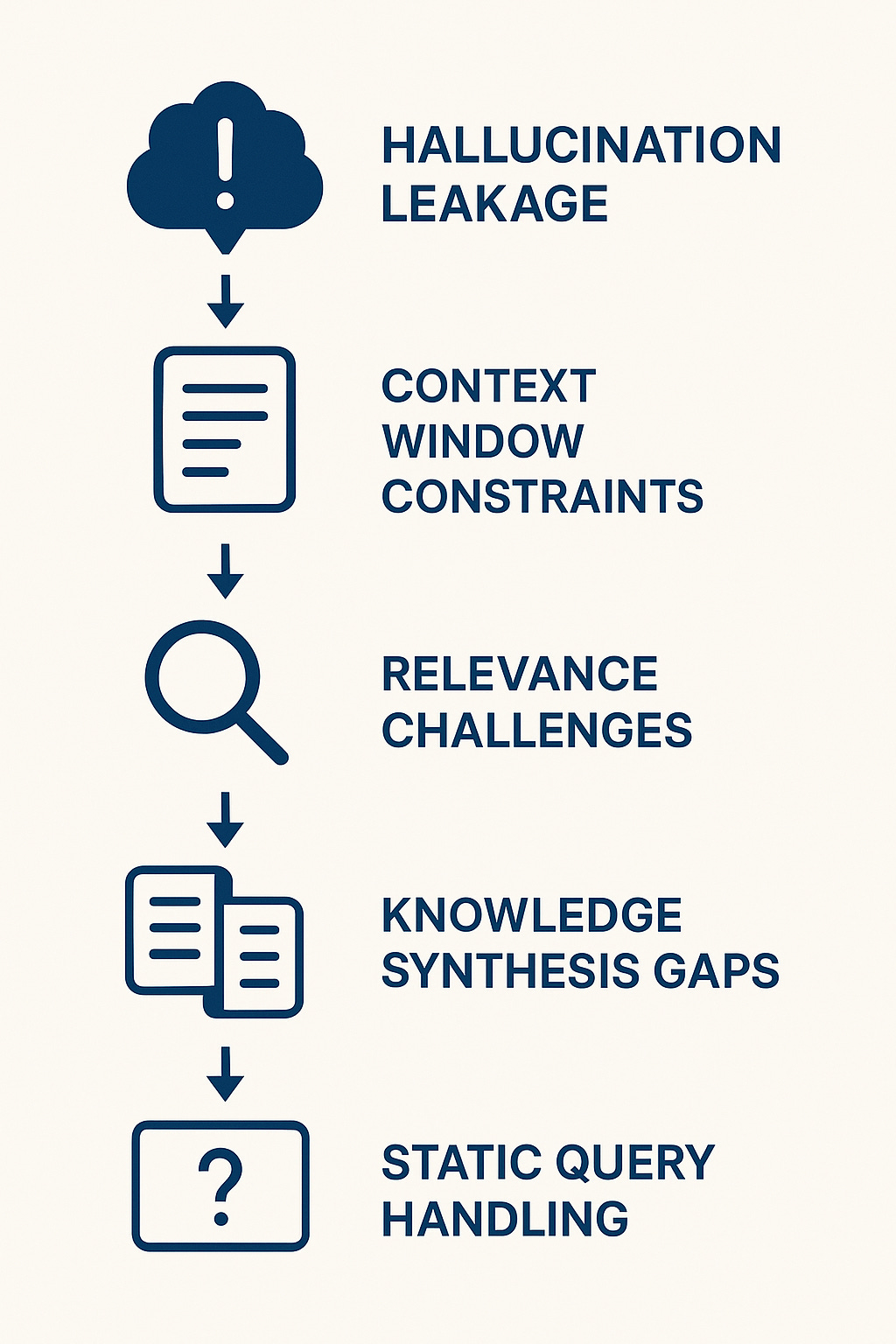
Traditional RAG systems follow a simple flow: query → retrieve relevant documents → generate response. While revolutionary compared to standalone LLMs, this approach has significant limitations:
Hallucination leakage: Even with retrieval, models often blend factual information with fabricated details
Context window constraints: Limited by how much retrieved information fits in the prompt
Relevance challenges: Struggling to find the truly relevant information among similar documents
Knowledge synthesis gaps: Difficulty connecting information across multiple sources
Static query handling: Unable to adapt retrieval strategies based on the complexity of questions
Basic RAG got us 70% of the way there. The race now is for that remaining 30%.
Multi-Stage RAG: The Breakthrough Approach
The most significant advancement in RAG architecture is the shift from single-step to multi-stage retrieval pipelines. Here's how it works:
Initial broad retrieval: Cast a wide net using semantic search
Re-ranking: Apply more sophisticated relevance filters to narrow results
Recursive retrieval: Use initial results to generate better queries
Cross-document reasoning: Connect information across multiple sources
Synthesis with verification: Generate responses with explicit source validation


🔍 POLL
3 Advanced RAG Patterns You Should Know
1. Hypothetical Document Embeddings (HyDE)
Traditional embedding approaches struggle with the "vocabulary mismatch problem" - when your query uses different terms than your documents.
HyDE flips the script: it first generates a hypothetical ideal document that would answer your query, then uses that document (not your original query) to search for similar real documents.
Results: 23% improvement in retrieval accuracy for complex queries across multiple benchmarks.
Implementation tip: Start with domains where terminology is particularly specialized or varies significantly between experts and users (healthcare, legal, technical support).
2. Self-Reflective Retrieval Chains
This architecture adds a critical reflection step where the model:
Evaluates the quality of retrieved documents
Identifies information gaps
Formulates follow-up queries to fill those gaps
Only proceeds to response generation when sufficient information is gathered
This mimics how humans research: we don't just search once and accept whatever we find.
Key innovation: Modern implementations use dedicated validation models that specialize in evaluating information completeness, separate from the primary retrieval and generation models.
3. Recursive Retrieval-Generation
This approach breaks complex queries into sub-questions that can be answered independently, retrieves information for each, then synthesizes a comprehensive response.

For example, answering "How might AI affect climate change solutions?" might involve separate retrievals for:
AI applications in energy optimization
Climate modeling improvements with machine learning
Policy implications of automated decision-making
The final response integrates these distinct knowledge areas.
Why it matters: As AI adoption grows, users ask increasingly complex questions that span multiple domains. Single-retrieval approaches break down when faced with these multi-faceted queries.
Technical Components for Effective RAG
Embedding Models
Several options are available depending on your requirements:
OpenAI's text-embedding models
Open-source alternatives like sentence-transformers
Domain-specific models for specialized applications
The choice of embedding model significantly impacts retrieval quality and should be evaluated for your specific use case.
Vector Databases
According to McKinsey the RAG process involves creating "dense vector representations" or "embeddings" of content, which requires efficient storage and retrieval systems.
Popular vector database options include:
Chroma: Good for prototyping and smaller implementations
Weaviate: Strong hybrid search capabilities
Pinecone: Managed service with strong performance
Milvus: Open-source option with community support
Qdrant: Specialized filtering capabilities
Each option offers different trade-offs in terms of performance, scalability, and features.
Implementation Considerations
Start with Clear Objectives
Define specific metrics to track improvement:
Response accuracy on domain-specific questions
User satisfaction and trust metrics
Operational efficiency gains
Error rate reduction
Modular Architecture
Design for flexibility and future enhancement:
Separate embedding, retrieval, and response generation components
Enable independent optimization of each component
Allow for seamless integration of new models or techniques
Data Quality Focus
As noted by BCG "The basic RAG architecture is relatively straightforward," but "each of these processes... are critical to success. Indexing, for example, essentially maps out a vast sea of data into a navigable landscape."
Success often depends more on data quality than algorithmic complexity:
Well-structured source documents
Appropriate chunking strategies
Regular knowledge base maintenance
Clear metadata and tagging

Addressing Implementation Challenges
Research published in a recent arXiv paper emphasizes that evaluating RAG systems presents unique challenges due to "their hybrid structure and reliance on dynamic knowledge sources," requiring assessment of multiple factors including "relevance, accuracy, and faithfulness."
Common challenges include:
Quality assurance: Ensuring retrieved information is reliable and up-to-date
Scalability concerns: Managing computational resources as knowledge bases grow
Integration complexity: Connecting RAG systems with existing enterprise tools
Governance and security: Maintaining appropriate access controls and audit trails
Organizations that proactively address these challenges position themselves for more successful implementations.
Future Directions in RAG
As RAG continues to evolve, several key trends are emerging:
Multi-modal RAG: Systems capable of retrieving and reasoning across text, images, and other data types
Tool-augmented retrieval: Integration with databases, APIs, and computational tools
Personalized knowledge contexts: Adapting to user expertise and preferences
Federated knowledge access: Retrieving from multiple sources while respecting security boundaries
These developments promise to further expand RAG capabilities and use cases.
One Thing To Try This Week
Add a simple validation step to your RAG prompts that asks the model to verify its response against the retrieved information before finalizing its answer. This lightweight addition can significantly improve response quality.
Example prompt addition:
Before generating a final answer, please verify:
1. Is your response fully supported by the retrieved information?
2. Are there any statements that go beyond what's in the source material?
3. Have you addressed the core question completely?
If information is insufficient, acknowledge this in your response.
📚 Resources
Article: McKinsey's RAG Explainer - Clear overview of concepts and applications
Tool: LlamaIndex - Open-source toolkit for building RAG applications
📣 Found this valuable? Share it with a colleague who's working with AI knowledge systems!
The Product Channel delivers weekly insights on AI, product strategy, and technology trends. Subscribe for free to join 9000+ professionals staying ahead of the curve.